Whether its myself or some other person performing the installation/implementation of a SyteLine ERP system you can bet the farm that somewhere in conversation this table was mentioned as one that needs to be kept neat and orderly. Hopefully everyone has a SQL Agent job or Execute TSQ task in their maintenance plan that keeps this clean but it’s not always clear to customers as to how and why this table gets dirty and why the frequency of the task may not always be weekly but in many cases could be hourly (yes this is not a typo!).
Infor has meticulously thought out their SyteLine product very well to ensure that data going into their system has proper referential integrity and as a result there are fewer and fewer data scrubbings that now occur between version upgrades. For those that used to be on the Progress based versions of the software and then upgraded, there was a lot of clean-up. Job routings could easily exist for jobs that do not exist and item location records could exist for an item that did not exist.
Many of these issues were brilliantly resolved through check constraints, foreign keys, and cascading triggers so now there is little to no chance of duplication on critical values such as vendor numbers, customer numbers, order numbers, and invoice numbers. Now comes the fun part: ensuring that the next value for a particular sequence can be obtained quickly when a function is called to ask for the “next in sequence” value.
The idea behind NextKeys is actually quite brilliant and when the table is clean, functions can snap the current value for a particular table/column value with lightning speed without performing a table scan. SyteLine will both read the values from this table and also add more current values as they change but one thing it will not do is perform an automatic real time purge of old values each time a function requests the most current value. The reason it does not delete the value is not an oversight by the creators but a safeguard to ensure that this is performed outside of a nested transaction so that a record lock will not occur and also so that in the event the “next value” was not committed to the database it won’t skip over that value altogether.
Many customers will often ask why their NextKeys table grows so quickly and the stock answer I usually give is that the growth of NextKeys is dictated not only by frequency of the sequences changing by a human but also many developers will write mods that utilize NextKeys and can contribute massive amount of records to this table in short order via automated tasks.
There are two combinations of data that comprise NextKeys:
TableColumnName + KeyPrefix should be 100% distinct (no duplicates) and should have only the the most current KeyID present(assumes subkey is not present)
OR
TableColumnName + SubKey should be 100% distinct (no duplicates) and should have only the most current KeyID in the list (assumes KeyPrefix is not present)
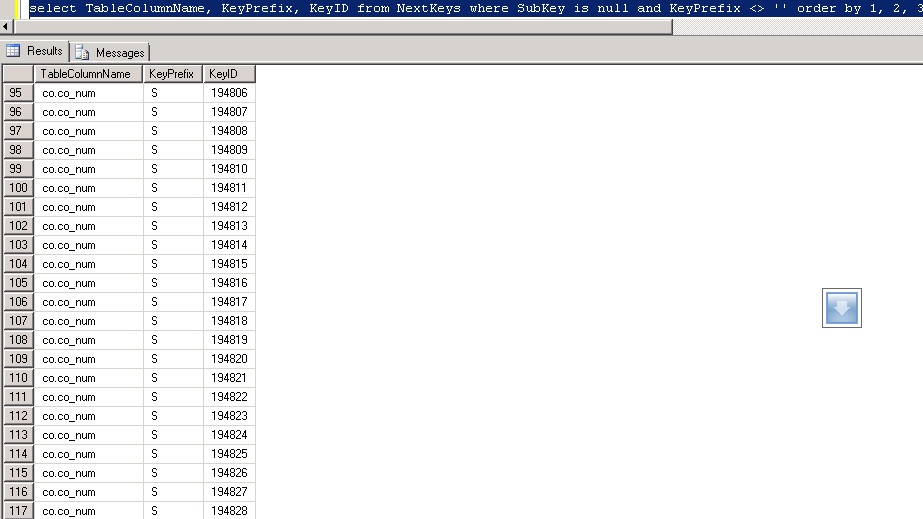
In the above example of an uncleaned NextKeys table you will see that co.co_num with KeyPrefix of S has many KeyID’s. There are 23 duplicates visible on the screen that after running PurgeNextKeysSp should leave one single record for this combination with a KeyID value of 194828.
Here is the same query after running the built in stored procedure to purge:
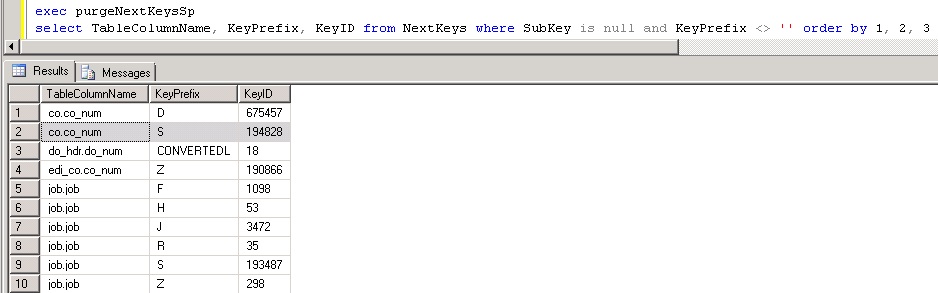
Notice how for each table/column key prefix there is only one KeyID that holds the most current (highest) value? This is what we want to see occur for performance reasons. Since this is a HEAP table, it’s especially important to keep it free of excessive clutter.
Product documentation describes the best practice of purging unneeded records from this as a nightly task. For most people I completely agree with this. There are some exceptions where mods that automate the insertion of records into this table will bloat it very quickly and for those customers who pass the threshold of over 2000 inserts per hour I would probably look into executing the PurgeNextKeysSp stored procedure multiple times per day and in some cases it may even be warranted hourly. For those who are worried about performing this task in the middle of the day, I would say that it would be highly unlikely for this task to take more than 5-10 seconds and it should not cause a disruption to users in the system like a reindex would cause on SQL Standard which forces many maintenance task to occur offline.
Something that really isn’t talked about too much is that NextKeys are 99.99999% correct for their values but there are certain circumstances where the current value on the NextKeys table is incorrect and desynchronized. It’s not that someone did something incorrectly in the system that caused it but likely a fluke hiccup resulting from the rare possibility of two getting and setting the NextKeys table at the exact split second and it causes the system to be report a usable next that truly is no longer available. I saw this more frequently in SyteLine 8.02 and earlier and not so much in 8.03 and newer. Infor has graciously provided a form called “Synchronize NextKeys” that will go through the process of finding the true value of what the NextKeys should be for each and every combination and assume all the values in this table could be incorrect. Depending on how many values are in this table it could take from a few seconds to many minutes to complete and should resolve error messages from SQL stating that it cannot insert a record because it already exists with that given combination.
The last nuance to discuss regarding the NextKeys table (and this is actually not specific to this table but any table that is a HEAP) is the bloat, forwarded records, and ghosted records that manifest itself and how to correct. Eventually I plan to make another article dedicated to this but for now I will simply provide a quick query to determine if the HEAP table suffers from this behavior HERE. Without going into too much detail you will not want to see any forwarded records, ghosted records or high fragmentation and if you see 10,000+ pages with only a couple hundred records it’s definitely bloated up. The fix for this only exists in SQL 2008 and newer and you would go into management studio and type
ALTER TABLE NextKeys REBUILD
After running that command you should be able to re-run the script to check it and see that everything is now clean, neat, and orderly.
Footnote for DBA’s:
For those of you who want to run the queries I ran to come up with the mathematical logic, here they are for your own curiosity:
select TableColumnName, KeyPrefix, KeyID from NextKeys where SubKey is null and KeyPrefix <> '' order by 1, 2, 3 + select TableColumnName, SubKey, KeyID from NextKeys where KeyPrefix = '' order by 1, 2, 3 = select count (*) from NextKeys
How many duplicate records can be found in NextKeys:
SELECT TableColumnName ,KeyPrefix [KeyPrefix or Subkey] ,count(*) TotalCount FROM NextKeys WHERE SubKey IS NULL AND KeyPrefix <> '' GROUP BY TableColumnName ,KeyPrefix HAVING count(*) > 1 UNION ALL SELECT TableColumnName ,SubKey [KeyPrefix or Subkey] ,count(*) TotalCount FROM NextKeys WHERE KeyPrefix = '' GROUP BY TableColumnName ,SubKey HAVING count(*) > 1 ORDER BY 1 ,2 ASC